Overview
Exercise Files
About Lesson
- Visit Google’s Teachable Machine website: https://teachablemachine.withgoogle.com/train
- Start a new project. Since we want to do a brief demo of this system, we will focus on using webcam-based still images for training data, so be sure to click on Image Project. In a later lesson in the full course, we will work with Audio and OpenPose as well; these take more time to train, so for now we will only work with images. Be sure to click on “Standard Image Model”
- After choosing Standard image model, make sure that your webcam is installed and turned on and you should see a webcam stream appear under Class 1.
- Be sure to have some objects ready (stuffed animals, hats, anything on your desk), and type in a name for your Class 1 object.
- Click on Webcam, and Hold for Record. Then, take at least 50 pictures, and closer to 100 pictures, of the object, with different orientations.
- Repeat this process for a different object, using Class 2 (lower on the screen).
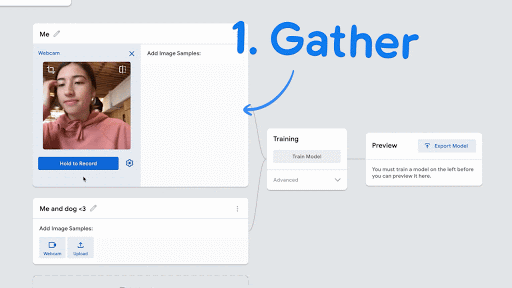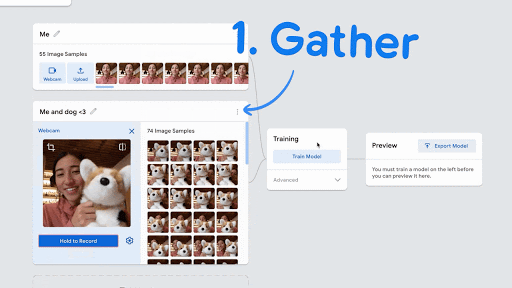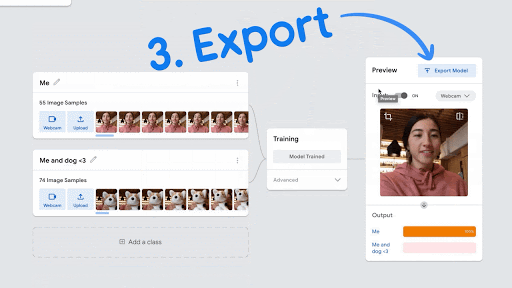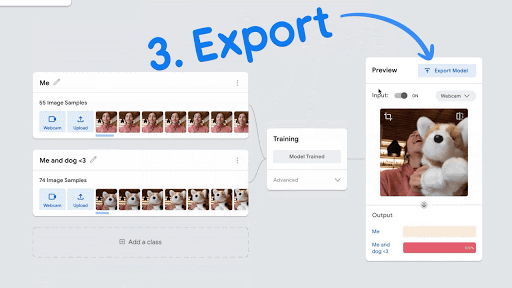
- Then click on “Train Model” in the center, and wait for it train your first AI model. After it is trained the Train Model button will turn grey, and you will see that your webcam is enabled on the right hand frame, to test your objects.
- Try testing your different objects, as well as objects that you didn’t use to train either Class 1 or Class 2, and see the results:
- Try variations, including both of the training objects at the same time, and different lighting. When you show both object to the webcam, do the Outputs appear to be close to 50%-50%? Is this what you would expect?
- Record some of your results, taking note of the use of different objects, and experiment to see how different conditions affect the results.
- Think about the following points, and come up with some conclusion about the system’s overall abilities and what might be the best way to train a Teachable Machine model:
Discussion Points for Teachable Machine Activity
- Do different quantities of training image samples make a difference as to whether or not the model accuracy is high or low?
- When you show 2 different objects to the camera, at the same time, does one outcome look higher than another? Why might that be? Was one more trained more than another, or did one have more variety of orientations?
- Does the system seem “prefer” one type of an object? Or prefer one type of lighting?
- If you trained the system with very different objects (like we did here in the example, using a chicken and a cat) versus training the system with very similar objects (like two different types of blue hats or two balls with similar colors), are the results different? Do you need more training when the objects are very similar?
- Do you thiink the system is very accurate?
- How many training images might be the minimum amount you need to get good accuracy?
Exercise Files

No Attachment Found